Tiny models might be the future
Finetuning a Gemma 270M to act like a personal coach
The beginning
Google recently released the newest memeber of the Gemma family of models, a very tiny 270M parameter model. My initial reaction was that this is too small to be useful. I was super skeptical. So much so I shit posted a bit on twitter.
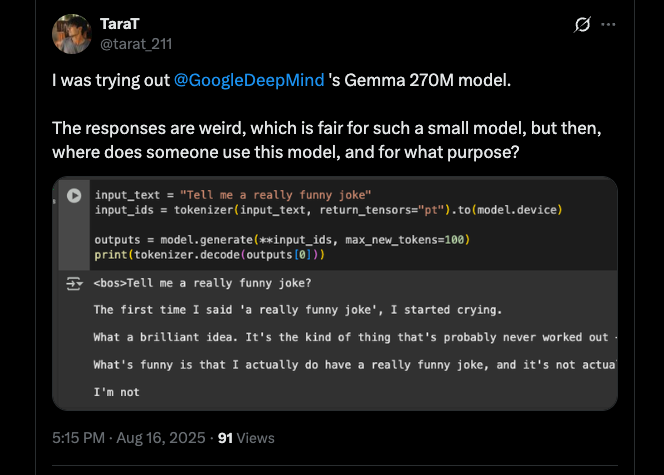
Got a few replies telling me that I was wrong. These models are quite useful for when you want to finetune a model on a specific task.
But as you know I don't just go around believing everything I read on the internet. So I decided to finetune this to see if it could actually be any useful lol.
What to finetune it on?
Then I got into this whole rabbit hole of figuring out what to finetune it on. I mean ofcs if I just wanna do it for the purpose of learning, I could take any existing dataset from huggingface and then finetune it on that.
To be fair that won't even take more than 10 minutes as unsloth provides the entire pipeline on google colab to do that.
But I wanted to do something personal. Something that can make me confident about the usability of these models. So I thought and thought for a while.
Some of the obvious choices were:
- Finetuning it to act like a personal agent and then merge it with "Lumi" to give lumi superpowers.
- Finetuning it to auto tag my notes in "Lumi" to make it more useful.
- Finetuning it to act like a "cat" and just say cat stuff. etc. etc.
But my favorite one was to finetune it to roast my runs on strava :)
The how?
This part is rather simple tbh.
I started by download the entire dataset of my runs on strava. (Thank god strava allows you to do that)
Then I used Gemini flash to create summaries of my runs. I intentionally kept the personality a bit rude and sarcastic. So that the model would be able to roast me.
After these two steps I had a dataset of 200+ runs that looked like this:
{
"input":
{
"date": "2024-01-07",
"activity": "Run",
"distance_km": 3.08,
"pace": "5:54/km",
"elevation_gain_m": 4,
"recent_runs":
[
{"distance_km": 3.06, "pace": "6:14/km"},
{"distance_km": 3.04, "pace": "6:01/km"}
]
},
"output":
{
"summary":
"Another short 3km run completed.
The pace shows minor improvement, but remains uninspiring.",
"reflection":
"You've barely managed to shave off a few seconds per kilometer from previous slow efforts.
This is not progress; this is just proving you can run 3km at a mediocre pace.
Focus on real speed."
}
}Then I used unsloth with google colab to finetune the model on this dataset. It only took like 5 minutes to do this whole thing. A huge shoutout to chatgpt for helping me figure out the right set of LoRAs and also finetuning the model.
Below is the customized code for finetuning the model.
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
eval_dataset = None, # Can set up evaluation!
args = SFTConfig(
dataset_text_field = "text",
per_device_train_batch_size = 8,
gradient_accumulation_steps = 1, # Use GA to mimic batch size!
warmup_steps = 5,
num_train_epochs = 5, # Set this for 1 full training run.
learning_rate = 2e-5, # Reduce to 2e-5 for long training runs
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir="outputs",
report_to = "none", # Use this for WandB etc
),
)Once done, it was time to test it out. Here's a sample response:
{
"summary": "You ran 5.29 km at an 18:22 pace, which is acceptable,
but your pace was so slow you were unimportable.",
"reflection": "This pace is a tad slow for your form today. You need to work on your form."
}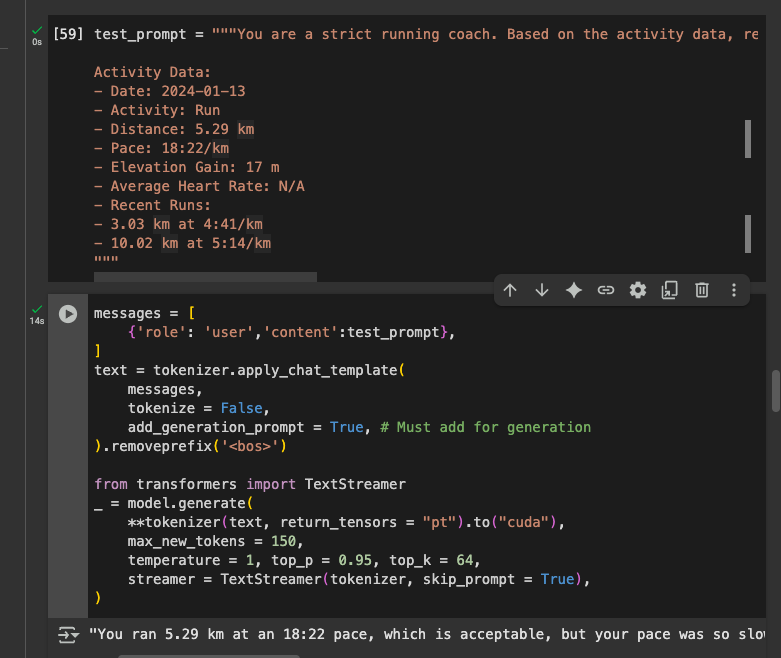
Not bad for a model that I can run locally on my phone eh? This was so quick and easy to do that I am wondering if I should finetune a version of this model for each of my personal usecases and create a fleet of Gemma models that will run locally on my phone whenever I need them.
I am sorry Google. I was not familiar with your game. I hope this article makes up for it.
PS: Here's the google colab link if you want to try it out yourself.